mirror of
https://github.com/JayWP/wp-kb-vault.git
synced 2026-06-04 10:15:15 +08:00
Added comprehensive guide on knowledge management using AI and the LLM Wiki approach, including setup instructions and core operations.
215 lines
5.6 KiB
Markdown
215 lines
5.6 KiB
Markdown
不是让你"更好地存资料",是让知识自己长出来。
|
||
|
||
先看看你是否也有这样的痛点:
|
||
|
||
- 读了一堆文章,存进笔记软件,过三个月再找,完全不记得存过;
|
||
|
||
|
||
- 扔进去的时候以为"以后会用到",实际上就是堆在那儿吃灰;
|
||
|
||
|
||
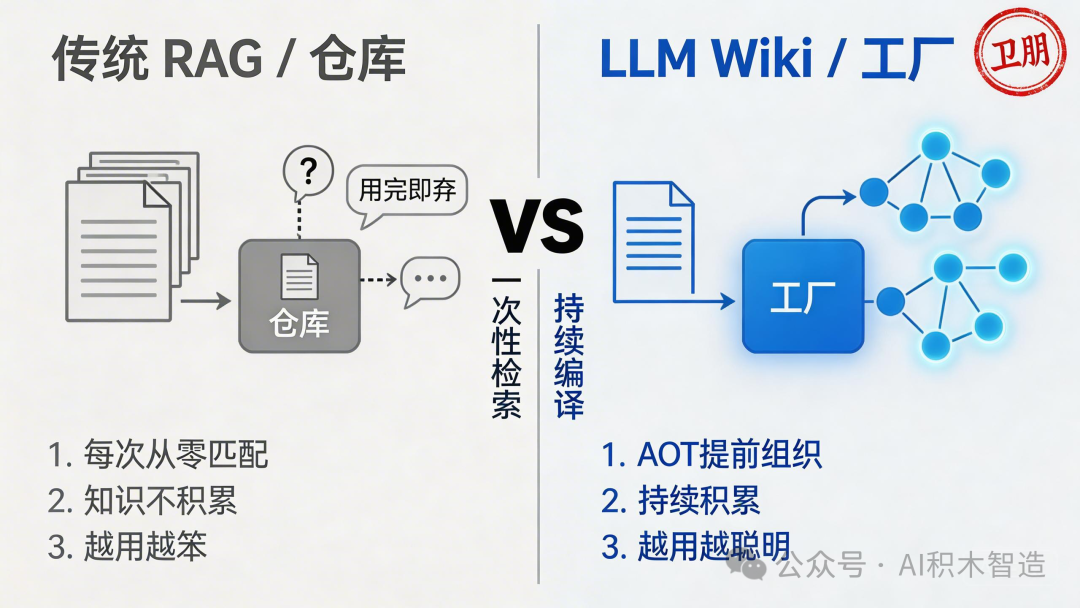
- 传统的知识管理是"仓库思维"——往里塞,塞完完事。
|
||
|
||
|
||
AI 来了之后,有人想了个办法:
|
||
|
||
RAG,检索增强生成。
|
||
|
||
你问问题,AI 从文档里找相关内容,拼一段答案给你。
|
||
|
||
听起来解决了"找不到"的问题,对吧?
|
||
|
||
但 RAG 有一个明显的缺陷——
|
||
|
||
知识永远停在原始文档里,从来没有被提炼、交叉、升级。
|
||
|
||
你问一次,它就临时找一次。
|
||
|
||
第二次问同一个问题,它还是从零开始匹配。
|
||
|
||
越长的项目,RAG 越不好用。
|
||
|
||
因为中间过程的积累全都丢了。
|
||
|
||
|
||
|
||
|
||
|
||
Karpathy 干了件什么事
|
||
|
||
2026年4月,AI 大神 Andrej Karpathy 在 GitHub 发了一篇 LLM Wiki,把这个问题想清楚了。
|
||
|
||
他没搞新模型,没搞新算法。
|
||
|
||
他就做了一件事:
|
||
|
||
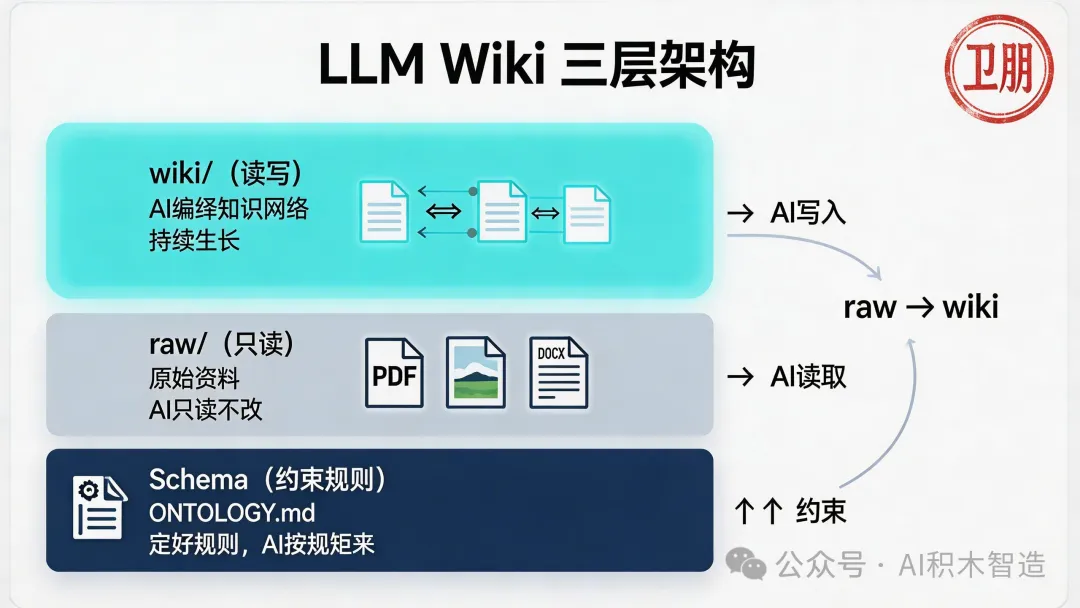
把知识库从"临时检索"模式,变成"持续编译"模式。
|
||
|
||
核心就三句话:
|
||
|
||
- Raw(只读):原始资料扔进去,AI 只能读,不能改
|
||
|
||
|
||
- Wiki(读写):AI 主动提炼、总结、建立链接,每次问答都让知识变厚
|
||
|
||
|
||
- Schema(约束):定好规则,AI 按规则更新,不乱来
|
||
|
||
|
||
|
||
|
||
简单说:
|
||
|
||
RAG 是"一次性检索",LLM Wiki 是"持续编译"。
|
||
|
||
每次你问问题,答案写进 Wiki,知识就在那里累积。
|
||
|
||
下次再问,AI 直接从已有的知识结构里调取,还能发现矛盾、发现关联——
|
||
|
||
这是真正的复利。
|
||
|
||
Karpathy 实测:在中等规模(约100个来源,数百页)下,这套方法比向量 RAG 好用得多。
|
||
|
||
|
||
|
||
我把这个方法做成了一个工具
|
||
|
||
基于 Karpathy 的 LLM Wiki 理念,打造的一个skills,即插即用。
|
||
|
||
工具栈:Obsidian + Git + AI Agent。
|
||
|
||
这是我用的环境,也可以用到龙虾这些场景。
|
||
|
||
核心架构(和 Karpathy 的 LLM Wiki 完全一致):
|
||
|
||
```
|
||
知识库/
|
||
```
|
||
|
||
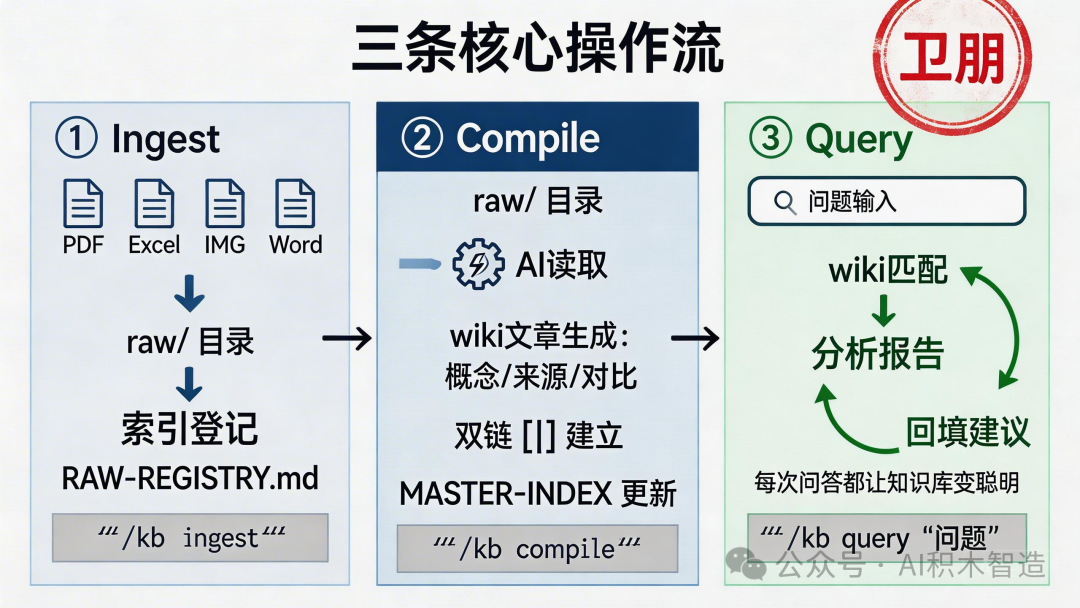
三条核心操作流:
|
||
|
||
① 吸收(Ingest)
|
||
|
||
新资料扔进 raw/,运行
|
||
|
||
/kb ingest,工具自动识别 PDF、Excel、图片(OCR)、Word,按类型提取文本,登记到索引。
|
||
|
||
② 编译(Compile)
|
||
|
||
运行 /kb compile,AI 读取原始资料,按 ONTOLOGY.md 的规则生成 wiki 文章。建立双链、交叉引用、更新索引。
|
||
|
||
③ 查询(Query)
|
||
|
||
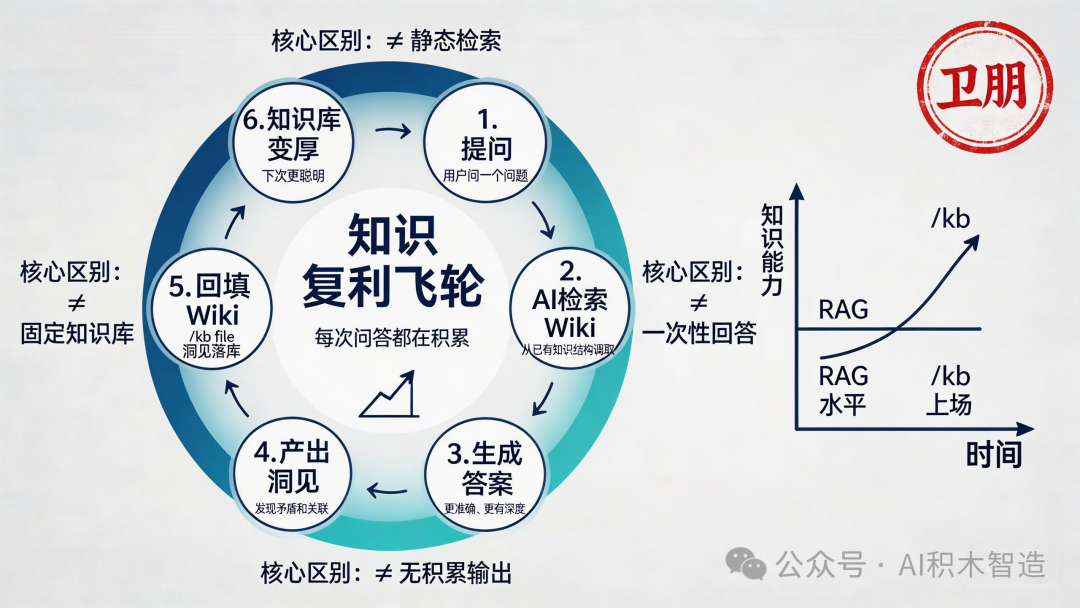
问一个问题,运行 /kb query "你的问题",AI 从 wiki 里找相关文章,合成答案,
|
||
|
||
同时把这次问答的洞见回填进 Wiki。
|
||
|
||
这就是复利的来源——
|
||
|
||
每个问答都在让知识库变聪明。
|
||
|
||
|
||
|
||
|
||
|
||
具体怎么用
|
||
|
||
第一步:初始化
|
||
|
||
在目标目录跑:/kb init [目录名]
|
||
|
||
例如给外部文件夹建知识库:
|
||
|
||
/kb init ~/my-research
|
||
|
||
或在当前 vault 跑,它自动检测是否已有知识库,没有就新建全套目录结构。
|
||
|
||
第二步:扔资料进去
|
||
|
||
把 PDF、Excel、图片、Word 文件放进 raw/
|
||
|
||
目录,运行:/kb ingest
|
||
|
||
它会:自动识别文件类型,提取文本
|
||
|
||
更新 RAW-REGISTRY.md(登记每份资料)
|
||
|
||
报告处理结果
|
||
|
||
第三步:编译成知识
|
||
|
||
资料有了,运行:/kb compile
|
||
|
||
AI 会:逐个读原始资料
|
||
|
||
按 Ontology 规则生成 wiki 文章(概念页/来源页/对比页)
|
||
|
||
用 [[双链]] 建立关联
|
||
|
||
更新 MASTER-INDEX.md(全局索引)
|
||
|
||
第四步:问问题
|
||
|
||
/kb query "RAG 和 LLM Wiki 的核心区别是什么"
|
||
|
||
AI 从 wiki 里找相关文章,分析、对比,输出报告到 output/analysis/。
|
||
|
||
而且,报告里会有一条"回填建议"——告诉你在 Wiki 里新建或更新哪些文章,能让这次问答变成可积累的知识。
|
||
|
||
第五步:回填(可选)
|
||
|
||
/kb file [报告路径]
|
||
|
||
把分析报告里的洞见落进 wiki,索引自动更新。
|
||
|
||
|
||
|
||
维护:健康检查
|
||
|
||
/kb lint
|
||
|
||
跑六项检查:断链、孤岛、溯源、一致性、覆盖度、空白发现。像跑测试一样保证知识库健康。
|
||
|
||
|
||
|
||
这和 RAG 比,到底强在哪
|
||
|
||
RAG 是"仓库",kb 是"工厂"。
|
||
|
||
仓库只进不出。
|
||
|
||
工厂加工原料,产出半成品,再加工,再产出——每一轮都比上一轮更有价值。
|
||
|
||
|
||
|
||
适合谁用
|
||
|
||
适合你如果:
|
||
|
||
- 正在做 AI 落地咨询,有大量客户案例、行业资料要管理;
|
||
|
||
|
||
- 长期跟一个领域,需要持续积累、交叉比对;
|
||
|
||
|
||
- 想让 AI 不只是工具,而是真正的"第二大脑"。
|
||
|
||
|
||
暂时不适合:
|
||
|
||
- 只是随手记笔记,不需要长期积累;
|
||
|
||
|
||
- 追求"存得快",不在意"用得上"。
|
||
|
||
|
||
|
||
|
||
工具获取
|
||
|
||
完整的 /kb 命令工具已开源,地址:
|
||
|
||
```
|
||
👉 https://github.com/JayWP/wp-kb-vault
|
||
```
|